前編では分類モデルを使用してalvaBuilderによるde novo生成を行いましたが、後編では回帰モデルを使用して自動生成を行ってみます。
《課題2》
Ø ゴール:与えられた特定の部分構造パターンを保持・除外しながら、ある分子に対する類似度を最大にするdecorator hopを行い、また、脂溶性logDの推算値がある値の範囲内に入るような分子セットをデザインする
課題2のゴールを達成するために、まず、オクタノール/水分配係数logDを推算する為の回帰モデルを準備します。
使用するデータセットの説明にも述べましたが、ここで推定する脂溶性の指標であるlogDは、広く使われているlogP(logPow)に対して電離による分子の脂溶性の変化を考慮に入れたものということになります。logPとそれに関連した指標は分子記述子としてalvaDescのMolecular propertiesブロックに含まれているため、それらを用いてlogDの推算モデルを構築するようなことにならないよう、alvaDescからalvaModelに受け渡す記述子から外しておかねばならないことに注意しました。
【alvaDescによる記述子・FP計算とプロジェクトファイルの出力】
alvaDescに2100分子のLipophilicityデータを入力し、3D記述子とlogPに関連した10個の記述子(#5196 MLOGP~#5202 ESOL、#5210 BLTF96~#5212 BLTA96)を除く4169個の記述子と、ECFP、PFP、MACCS166のフィンガープリントを計算させます。ECFP/PFPは課題1と同様、デフォルト設定のままで計算させます。
また、外部変数としてLipophilicityのlogD実験データをインポートし、課題1と同様に変数削減ツールを使用して記述子数を減らしておきます。ここでは4169個の記述子が1178個に減りました。このデータにLipophilicityの実験データをインポートした上で、Lipophilicity_2100_1178desc.adprjというプロジェクトファイルとして保存します。
【alvaModelによる脂溶性回帰モデル作成】
上で作成したプロジェクトファイルをalvaModelにインポートします。2100個の分子データは、Venetian blindでトレーニングとテストに分割します。トレーニングセットのサイズを60%とし、1260個のトレーニングと840個のテストができました。
モデル構築は、課題1と同じようにまず手動でフィンガープリントを使ったものをいくつか作ってみることとし、ECFPを選択し、PLS、KNN、SVMのモデルを作成しました。その結果、KNNモデルのR2は0.397とPLSの0.743、SVMの0.778に比べかなり劣っていることがわかりました。
次にPLSと分子記述子を使った回帰モデルの自動生成を行いました。特徴量の数=記述子数を10個、スコアはモデルの予測能力を評価するためにより良いと言われているQ2 (n-fold) とし、nは5にしました。Q2 (5-fold) は5分割されたトレーニングデータの組合せを変えて5回計算されるR2の平均を取るという交差検証(cross validation)を行いますので計算にとても時間がかかります。しかし、1つのトレーニングセットに過学習するようなことがないという点で、出来上がったモデルの予測能力をより正しく評価することができることになります。
ただ、遺伝的アルゴリズムの繰返しを10000回行い、モデルを生成しましたが、あまり芳しい結果は得られませんでした。[図23]
 [図23]
[図23]そこで、モデルをSVMに変え、記述子数を20に増やして自動生成を行いました。この計算はPLSより更に時間がかかり、使用しているIntel Core i5 2.11GHz 4コアのラップトップマシンをCPU 100%で3日間稼働させても10000回の繰返しが終わりません。しょうがないので途中でPauseボタンを押して切り上げました。[図24]
 [図24]
[図24]生成されたモデルはPLSよりはQ2の値が高いものの、スコア最大のモデルでもQ2が0.581と満足できる数値ではありませんでした。[図25]
 [図25]
[図25]上位5つのモデルをセーブしてから、今まで作られたモデルを比較してみます。最初に手動で作成した3つのモデルはScoreメニューからQ2を計算させました。[図26]
 [図26]
[図26]すると、R2ではモデル3のRegr SVM 3 ECFPが0.778とモデル9のRegr SVM 9 20descの0.678より良いのですが、Q2では逆にモデル3が0.497とモデル9の0.581より悪くなっていました。また、それらはトレーニングの値ですが、テストのR2を見ると、モデル3が0.498とトレーニングの0.778と比べると大きく差があるのに対し、モデル9ではテストのR2が0.535とトレーニングのR2
0.678から大きくは下がっていないことがわかります。これは、モデル9を生成した時にQ2をスコアとして使用した良い効果だと思われます。尚、Q2はトレーニングセットを分割して交差検証した結果の数値であるため、テストセットでは計算されません。
モデルのタイプや使用する記述子数をいろいろ変えることにより、更に良いモデルを生成することが出来ると思いますが、ここではモデル9を使用することとし、モデル構築を終えalvaBuilderによるde novo分子生成のステップに入ることとします。
モデル9をプロジェクトファイルとしてエクスポートする前に、AD(適用範囲)を設定します。ADはレバレッジと距離で計算させてみました。その結果、Q2が殆ど変わらず、テストのR2が良くなっている90パーセンタイルの距離をADとして採用し、プロジェクトファイルに含めることにしました。[図27]
 [図27]
[図27]【alvaBuilderによるde novo分子設計《課題2》】
それでは、課題2に沿って、alvaBuilderにchembl22_reduce.smiのトレーニングデータを入れ、decorator hopの設定をして行きます。
Ø CCCOc1cc2ncnc(Nc3ccc4ncsc4c3)c2cc1S(=O)(=O)C(C)(C)C と類似 [図28]
 [図28]
[図28]Ø [#7]-c1n[c;h1]nc2[c;h1]c(-[#8])[c;h0][c;h1]-c12 と合致 [図29]
 [図29]
[図29]Ø [#7]-c1ccc2ncsc2c1 と非合致 [図30]
 [図30]
[図30]Ø CS([#6])(=O)=O と非合致 [図31]
 [図31]
[図31]Ø Lipo回帰モデルで値が1~3の間
[図32][図33]
 [図32]
[図32]このモデルは先ほどADを設定しましたので、生成された分子がADの中に入るようにする条件にチェックをつけます。
 [図33]
[図33]Ø スコアの計算は算術平均
[図34]
 [図34]
[図34]この設定で母集団サイズを200、繰返しを300にして自動生成をスタートさせます。
開始から5分15秒で300回の繰返しが終了しました。生成された200個の最高スコアは0.751、最低スコアは0.735でした。[図35]
 [図35]
[図35]内容を見ていくと、合致ルールが厳しかったようで全てで合致無しですが、2つの非合致ルールは全て1でOK、類似ルールは類似度が0.677から0.757の範囲でした。モデルルールでは1~3の間になるよう設定しましたが、1以下のものは無く、3をわずかに超えるものが8個(3.004~3.056)ありましたが、ほぼ設定範囲内に入っているという結果でした。
生成された最もスコアが高い分子をFind inからGoogle Patent/Scholarで検索してみると、Full structureではnot foundでしたが、Similarityで類似検索するとGoogle Patentで3件ヒットしました。[図36]
 [図36]
[図36]PubChemの類似検索では30件がヒットしました。[図37]
 [図37]
[図37]次に、モデルルールの導入前と導入後を比べてみるため、スコアからモデルルールを外し、残りの4つのルールで走らせてみました。計算の進みが早く、300回の繰返し終了まで2分26秒しかかかりませんでした。モデルルールを入れた場合に計算時間が2.16倍長くかかっていたことになります。
生成された200個の分子のスコアは0.678~0.666と、先ほどの生成結果と比べると低くなったように見えますが、スコアが算術平均で計算されるため、モデルルールでほぼ1点取れていたものが無くなった効果と平均を計算する分母の数が1つ少なくなった効果を考え合わせると、むしろ良い結果と言えるかもしれません。[図38]
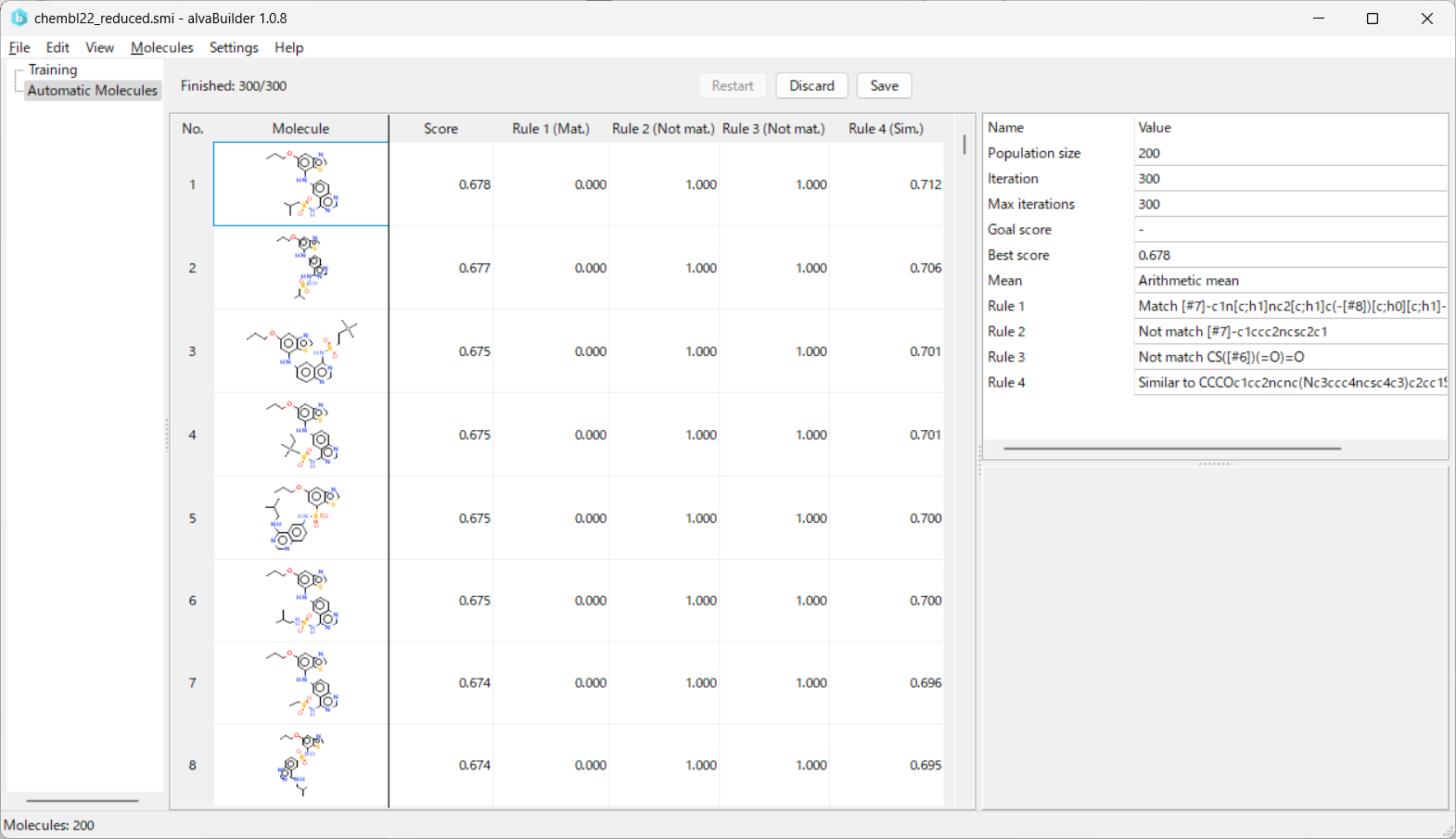 [図38]
[図38]では、このモデルルールなしで生成された200個の分子セットを保存し、alvaRunnerに入力し、モデルルールで使用したRegr SVM 9のモデルを適用しlogDを推算させてみます。[図39]
 [図39]
[図39]計算はすぐに終わりました。推算値は1.142から3.995となっており、3以上(greater than)でフィルターを掛けると112個になりました。[図40]
 [図40]
[図40]今回試してみた結果だけに限れば、モデルルールを使用すると、予測値の計算を行い、結果が設定範囲内にあるかないかを判断し点数付けをすることで分子の自動生成にかかる時間は2.16倍かかりました。また、生成された200個の分子の中で、予測値の設定範囲内に入ったものは192個でした。
一方、モデルルールを使用せずに自動生成を行うと計算は速くなりました。しかし、モデルによる予測値を生成の判断に入れていないため、生成された分子に対して別途予測値を計算させると、希望する範囲に入ったものは200個中88個しかありませんでした。モデルルールを使用したことにより、希望する範囲内に入った分子が2.18倍多くできたことになります。
自動生成に使ったトレーニングセットの27万個の分子をalvaRunnerにかけ、logDの推算値をSVM 9のモデルで計算させてみると、-1.491から4.818と広く分布しています。それにも拘わらず、モデルルールを使用せずに自動生成させた結果が希望する範囲からかけ離れたものになっていなかったことは、類似ルールで設定した分子のlogD推算値が3.030であったことに理由があると思われます。従って、使用するモデルルールが他のルールと関連性がない場合には今回と全く違う結果となることが予想されます。計算時間が倍かかろうとも、最初からモデルルールを組み込んで自動生成させることが、ゴールにより近い分子を効率的に入手する早道だと思われました。
⦅後編終わり⦆






