Alvascience社のソフトウェアスイートが2022年11月に一斉にバージョンアップされました。de novo分子生成ソフトであるalvaBuilderは、マイナーバージョンアップながら、要望の強かったQSAR/QSPRモデルの使用を生成ルールに組み込むことができるようになりました。これにより、Alvascience社ソフトウェアスイートの有機的な連携がより強化されています。
そこで、この記事では、alvaModelで作成したQSAR/QSPRモデルの使用を中心に、alvaBuilderを使ったde novo分子生成を実際のデータを使ってまとめてみました。
【ツール】
今回使用するツールは、
・alvaBuilder 2.0.8:遺伝的アルゴリズムを用いた新規分子設計(de novo design)
・alvaMolecule 2.0.2:分子データセットのキュレーション
・alvaDesc 2.0.14:分子記述子とフィンガープリント(FP)の計算
・alvaModel 2.0.6:alvaDescで計算された結果を使った回帰・分類モデルの作成
・alvaRunner 2.0.6:alvaModelで作成されたモデルの化合物データセットへの適用
の5つです。
尚、alvaDesc/alvaModel/alvaRunnerの連携使用の詳細については、弊社ブログ「Alvascience社Software Suite:alvaDesc/alvaModel/alvaRunnerの連携使用(前編)(後編)」をご参照ください。
https://www.affinity-science.org/2022/06/alvasciencesoftware-suitealvadescalvamo.html
【alvaBuilderによるde novo分子生成のゴールとルール】
今回はChEMBLデータベースに基づく化合物のデータセットを基に、2つの課題を設定してde novo分子生成を行ってみます。
-
課題1
Ø ゴール:バルサルタン*1に含まれるフラグメントパターンを持つが、ぺリンドプリル*2と似た物理化学特性を持ち、血液系・リンパ系への副作用がない分子セットをデザインする
Ø 設定するルール
² LOGPcons : 2.0~2.5(バルサルタンのLOGPcons = 4.1507、ぺリンドプリルのLOGPcons = 2.1130)
² TPSA(Tot) : 90~100(バルサルタンのTPSA(Tot) = 112.07、ぺリンドプリルのTPSA(Tot) = 95.94)
² SAscore : 4以下(バルサルタンのSAscore = 4.4151、ぺリンドプリルのSAscore = 4.1347)
² QED : 0.68以上(バルサルタンのQED = 0.5783、ぺリンドプリルのQED = 0.6926)
² SIDER(副作用データセット)に基づく分類モデルでBlood and
lymphatic system disorderが0(認められない)
² バルサルタンに含まれるフラグメントを固定 (C([R])([R])N(C([R])=O)Cc1ccc(-c2c([R])cc([R])cc2)cc1)
² スコアの計算は幾何平均
*1 高血圧治療薬(アンジオテンシンⅡ受容体拮抗薬)、CAS:137862-53-4
*2 降圧薬(アンジオテンシン変換酵素阻害薬)、CAS:82834-16-0
-
課題2
Ø ゴール:与えられた特定の部分構造パターンを保持・除外しながら、ある分子に対する類似度を最大にするdecorator hopを行い、また、脂溶性logDの推算値がある値の範囲内に入るような分子セットをデザインする
Ø 設定するルール
² 類似ルール(Similarity rule)CCCOc1cc2ncnc(Nc3ccc4ncsc4c3)c2cc1S(=O)(=O)C(C)(C)C
と類似
² 合致ルール(Match rule): [#7]-c1n[c;h1]nc2[c;h1]c(-[#8])[c;h0][c;h1]-c12
のパターンを含む分子を好む
² 非合致ルール(Not match rule): [#7]-c1ccc2ncsc2c1 のパターンを嫌う
² 非合致ルール(Not match rule): CS([#6])(=O)=O のパターンを嫌う
² Lipophilicity(脂溶性データセット)に基づく回帰モデルで、logDの値が1~3の間 *3
² スコアの計算は算術平均
² フラグメントの固定はなし
*3 Lipophilicity in drug discovery, Waring, M., Pages 235-248,
Expert Opinion on Drug Discovery Volume 5, 2010 - Issue 3, Published online: 26
Feb 2010, https://doi.org/10.1517/17460441003605098
【データセット】
・de novo分子生成に使用するトレーニングデータセット:chembl22_reduced.smi(SMILESファイル)
-
ChEMBL database
Ø ChEMBLデータベースは生理活性分子についてのドラッグライクな特性を提示するデータベースで、人力でキュレートされています。現在最新版はChEMBL 31で、230万を超える化合物が含まれています。
-
chembl22_reduced
Ø alvaBuilderによるde novo分子生成のトレーニングデータセットとしては、Grisoni *4らによりChEMBL 22 *5から抽出された計271,914個 *6のサブセットを使います。
*4 Grisoni, F., Moret, M., Lingwood, R.,
& Schneider, G. (2020). Bidirectional Molecule Generation with Recurrent
Neural Networks. Journal of Chemical Information and Modeling, 60(3),
1175–1183. https://doi.org/10.1021/acs.jcim.9b00943
*5 https://chembl.blogspot.com/2016/09/chembl-22-released.html
*6 サブセットを作成するための処理
1. 塩の除去、2. 電荷中和、3. 100文字以上のSMILES文字列を持つ分子の除去、4. H, B, C, N, O, F, Si, P, S, Cl, Se, Br, I以外の元素を持つ分子の除去、5. 販売されている10種類の薬品とのECFP4による類似度が0.323以上の分子の除去(celecoxib, aripiprazole,
cobimetinib, osimertinib, troglitazone, ranolazine, thiothixene, albuterol,
fexofenadine, mestranol)。
・課題1のモデルを作成するためのデータセット(分類モデル)
-
SIDER dataset
Ø SIDER(Side Effect Resouce)は市販されている薬とその副作用(ADR)のデータベースです。MoleculeNet *7に含まれているSIDERには、1427の承認された薬品について、MedDRA(国際医薬用語集)の分類に従った27の器官別大分類(System Organ Class、SOC)毎に副作用の有無がまとめられています。
Ø 今回は、この27の副作用の内、Blood and lymphatic system disorder(血液系・リンパ系への障害)を取り上げて二値分類モデルを作成してみます。ちなみに、1427の薬品の内、血液系・リンパ系への副作用があるものは885(62%)でした。
・課題2のモデルを作成するためのデータセット(回帰モデル)
-
Lipophilicity dataset
Ø MoleculeNetに含まれているLipophilicityデータセットは、ChEMBLデータベースに基づいて作成された、4200の化合物に対するlogD:オクタノール/水分配係数(octanol/water
distribution coefficient)の実験データです。脂溶性(Lipophilicity)は、膜透過性や溶解性に影響する薬物分子の重要な特性であり、電離を考慮しlog Pに酸解離定数pKaなどを加味したlogDはpHに依存します。このデータセットは血清の生理学的pH 7.4に対するオクタノール/水分配係数logD7.4 の実験値を提供しています。
Ø 今回は計算負荷を軽減する為、元の4200個のデータからランダムに抽出した2100個のデータを使い、回帰モデルを作成します。
・3つのデータセットの俯瞰比較
-
de novo分子生成に使用するchembl22_reducedデータセットと、分類・回帰モデルの作成に使用するSIDER/
Lipophilicityデータセットを簡単に比較するため、alvaMoleculeで分子量(MW)を計算させ、ヒストグラムを描画させてみました。それぞれヒストグラムの区分を10個として自動描画させていますので、X軸の取り方が違っています。そこで、X軸の200と600が合うように調整、表示してみました。[図2][図3][図4]
また、SIDERデータセットにはMWが大きな分子がいくつか含まれているため、描画の都合上、MWが1000以下の分子だけをalvaMoleculeで抽出した1335個のサブセットを使い、表示しています。[図1]
 [図1]
[図1]
分子量だけの比較ですが、分布の山のピークは違うものの、de novo生成のもととなる分子セットと、分類・回帰のモデルを作るための分子セットに大きな乖離はないものと考えました。
《課題1》
それでは、課題1のゴールを達成するために、まず、「血液系・リンパ系への副作用がない」ことを推定する為の分類モデルを準備することから始めます。
【alvaDescによる記述子・FP計算とプロジェクトファイルの出力】
alvaDescに1427分子のSIDERデータを入力し、3D記述子を除く4179個の記述子と、ECFP、PFP、MACCS166のフィンガープリントを計算させます。ECFPとPFPはカスタマイズできますが、ここではデフォルト設定のままで計算させます。
また、次のステップのモデル作成をより効率的に進めるため、外部変数としてSIDERの副作用データをインポートし、変数削減ツールを使用して記述子数を減らしておきます。今回は、一定値若しくは1つを除いて他が一定値、標準偏差が0.001以下、ペア相関係数が0.9以上の記述子を除き、4179個の記述子が1238個に減ったものをalvaModelに計算結果を渡す役割となるalvaDescプロジェクトファイルとして作成しました。[図5]
 [図5]
[図5]【alvaModelによる血液系・リンパ系への副作用分類モデル作成】
先ほど作成したalvaDescプロジェクトファイルをalvaModelにインポートし、Datasetsメニューからトレーニング/テストの分割を行います。SIDERデータセットにはトレーニング/テストを分けたカラムが含まれていないため、MoleculeNetの説明で推奨されているランダムスプリットを行います。トレーニングセットのサイズを70%とし、999個のトレーニングと428個のテストに分割しました。
このトレーニングデータを使い、まず手動でモデル作成を行ってみます。最初に分類モデルを選択し、手法としてKNN(K近傍法)、距離はJaccard/Tanimotoを選択、ターゲットとして「Blood and lymphatic system disorders」を選び、positive
classを0、特徴量としてECFPを指定し実行させるとモデルができます。同様にECFPを使い、SVM(サポートベクターマシン)、PLS-DA(部分的最小二乗判別分析)でもモデルを作成してみました。これら3つのモデルを比べてみると手法としてSVMを使ったモデルの性能が一番良いようです。フィンガープリントとしてMACCS 166を使いSVMモデルを作成してみましたが、SVM-ECFPよりは低い性能となりました。[図6]
 [図6]
[図6]次に、記述子を使ったモデルの自動生成に入ります。手法としてはSVMを採用してみることとして、モデルに使用する記述子数を10、母集団サイズを60、モデルを評価するスコアはBalanced accuracy、range scaleの前処理を設定して遺伝的アルゴリズム(GA)による自動生成をスタートさせます。GAの繰返しをデフォルトの10000回に設定してあることもあり計算にはとても時間がかかりましたが、出来上がったモデルの中でスコアが一番良かったものでもBalanced accuracyが0.757と、ECFPを使ったものに比べて大きく劣りました。そこで、モデル手法をKNNに変えて同条件で実行してみました。今度は途中でスコアが伸びなくなり、遺伝的アルゴリズムの問題点として挙げられている、初期収束による局所最適解に陥ったと思われる状況となってしまいました。[図7]
 [図7]
[図7]alvaModelではモデルの自動生成状況をリアルタイム表示してくれるので、このような状況を見てPauseボタンによりストップさせることができます。一般的には、初期収束・過剰適合を避けるために、突然変異比率を変えたり選択の方法を変えたりすることが行われるようです。alvaModelではそれらを変更できませんので、初期母集団を変えて再試行するか、モデル手法を変えて別途実行するようにした方が良さそうです。
alvaModelの大きなメリットの1つは、設定する手法や条件をいろいろ変えて自動生成した多くのモデルを用いてベストなモデルを探索して行くことができる点であると思われます。*8
*8 Methoxy
and methylthio-substituted trans-stilbenederivatives as CYP1B1 inhibitors –
QSAR studywith detailed interpretation of molecular descriptors (2022),
Piekuś-Słomka, N., Zapadka, M., Kupcewicz, B., King Saud University Arabian
Journal of Chemistry, Volume 15, Issue 11, November 2022, 104204, https://doi.org/10.1016/j.arabjc.2022.104204
ただし、今回はモデル構築が最終目的ではないので、手法をより計算負荷の少ないQDA(二次判別分析)に変え、記述子数を20、母集団サイズを120に増やした設定で再度トライしてみることにしました。
その結果、10000回の繰返しでトータル896個の記述子が試され、ベストモデルのスコアは0.741となりました。[図8]
 [図8]
[図8]これまで生成されたモデルの中では、ECFPに基づいたSVMモデルがベストスコアとなりました。トレーニングセットでのスコアはとても高い一方、テストセットに対するスコアが低いことが気になります。[図9]
 [図9]
[図9]それでも他に作られたモデルよりは良い性能となっていますので、このモデルClass SVM 2 ECFPを血液系・リンパ系への障害モデルとして採用することとし、Export
modelsメニューからalvaRunnerプロジェクト形式でエクスポートしておきます。
【alvaBuilderによるde novo分子設計《課題1》】
それでは、課題1に設定したルールに従ってalvaBuilderを設定し、新規分子を生成していきます。
まず、トレーニングセットとするchembl22_reduced.smiを読み込ませます。de novo生成の操作はいたって簡単で、メニューのMoleculesからAutomatic molecules generationのダイアローグを開き、設定するルールを記入するだけです。ルールのaddを押すと子画面が現れますので、descriptorルールを選択し、以下の値を設定します。[図10]
Ø LOGPcons : 2.0~2.5、TPSA(Tot)
: 90~100、SAscore : 4以下、QED : 0.68以上
 [図10]
[図10]次はいよいよ分類モデルの設定です。記述子ルールと同様にAddからModelを選ぶとモデルファイル(alvaRunnerプロジェクトファイル)選択画面が出ますので、先ほどセーブしたsider_blood.arpjファイルをopenします。するとプロジェクト詳細が表示されますので、内容を確認することができます。[図11]
 [図11]
[図11]OKを押すとモデルルール設定画面に選択したモデルが表示されます。このモデルではAD(適用範囲)は設定しませんでしたので、Molecule needs to be
inside Applicability Domainのチェックボックスはそのまま空白にしておきます。また、好ましいclassは副作用なしの0ですので、classは0とします。[図12]
 [図12]
[図12]OKを押せばスコアにモデルが加わります。また、下の方にあるスコアの各ルールの平均値を計算する方法を幾何平均にしておきます。[図13]
 [図13]
[図13]これでスコアの設定は終了ですので、Nextを押してフラグメント固定の設定に入ります。Addからフラグメント入力画面に固定するフラグメントのSMARTSを入力します。[図14]
 [図14]
[図14]ここでOKを押し、次のGenetic Algorithm設定画面に進みます。繰返しの回数が多くなるほど、また、母集団の大きさと最大繰返し数の積が大きくなるほどより好ましい(スコアが高い)分子が多く生成されてくることが分かっていますが、ここでは、デフォルトの母集団サイズ150、最大繰返し数100のまま進めます。Stop if Goal score reachedのチェックボックスをオンにすると、最大繰返し数に達する前でも、設定するゴールスコアに到達すれば、そこで新規分子生成はストップします。[図15]
 [図15]
[図15]設定のFinishを押すと自動生成が開始されます。
100回の繰返しが終了すると生成された結果が表示されます。内容を見ると、4番目以降の分子のスコアは0となっています。これは、スコアの計算を幾何平均としたため、モデルルールで副作用あり(=1)と予測されるとスコアが0点となるためです。また、スコアの最大値は0.049となっていますが、記述子個々の値は設定した範囲の外にあります。これは、記述子ルールで設定した範囲の外にあるものでも一律に0点とせず、より近いものに0と1の間の点数を付与するスムージングが行われているためです。[図16]
 [図16]
[図16]副作用の分類モデルによる予測値が厳しく働き、満足できる結果が得られませんでした。
そこで、もう一度、母集団サイズを300、繰返しを200とそれぞれ倍に大きくして再試行してみます。
今度は、123回目の繰返しの時にスコア=1の分子が出現したことにより自動生成がストップし、スコアが1の分子が2個できていました。また、副作用の予測値を見ると、最終的に残った300個の分子全で予測値が0(副作用なし)となっていることがわかります。[図17]
 [図17]
[図17]この結果はSaveボタンからSMILESフォーマットのファイル(.smi / .txt)[図18]、若しくはエクセルファイル[図19]として保存できます。
 [図18]
[図18] [図19]
[図19]ちなみに、生成されスコアが1であった2つの分子を、EditメニューにあるFind inからGoogle Patents/ScholarとPubChemで検索してみましたが、full structureで合致するものはありませんでした。
Googleの類似検索では、Google Patentからヒットがありました。[図20]
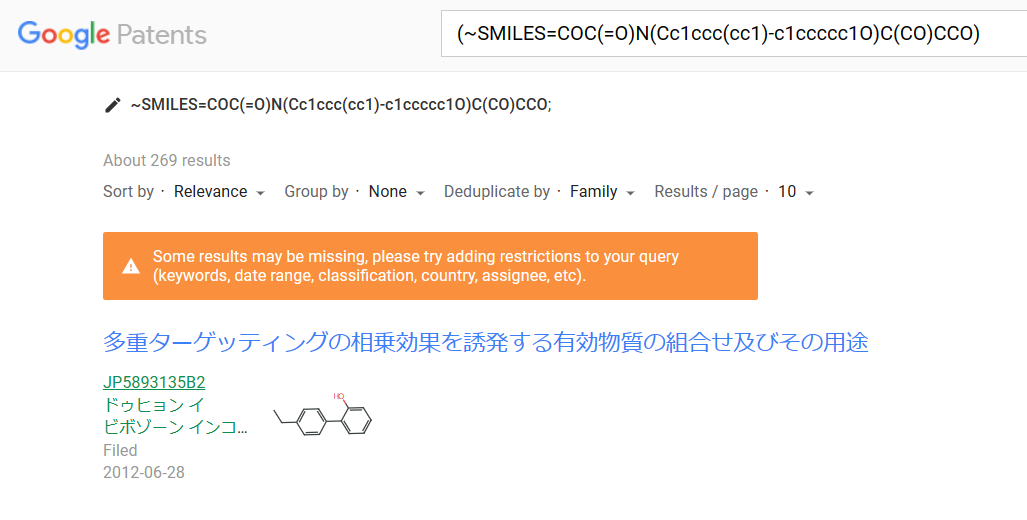 [図20]
[図20]PubChemの類似検索で類似度を90%に設定すると、No.1の化合物で1個、No.2の化合物で8個の化合物がヒットし、No.2の1つを除いた8つはChEMBLの化合物でした。
[図21]
 [図21]
[図21]これらの類似化合物が27万個のトレーニングデータに含まれているかをチェックしようと思いましたが、あいにくとトレーニングデータセットchembl22_reduced.smiにはCHEMBLxxxという名称のフィールドが含まれていませんので文字検索ができません。そこで、alvaMolecule 2.0の新機能である重複分析を使ってPubChemでヒットした分子がchembl22_reduced.smiに含まれているかどうか見てみました。ちょっと時間はかかりましたが、その結果、56の重複グループが検出されました。しかし、PubChemで類似とされた化合物と重複するものは27万個のトレーニングデータの中にはありませんでした。[図22]
 [図22]
[図22]つまり、トレーニングデータに基づいてde novo生成された分子は既に知られた分子の中にはないが、トレーニングデータ以外のChEMBLデータベースにある分子と似たものであったということになりました。
今回はゴールスコア=1を設定しましたのでそこでストップしましたが、一度全てのルールを満足するような分子が生成されると、それ以降は望む性質を持つ分子が次々と生成されることが予想されます。遺伝的アルゴリズムのロジックによりスコアが高いものは淘汰されずに生き残り、それらスコアが高いものを親として交差・突然変異により生み出された子と親をスコア順に並べ、スコアが高い上半分が生き残るということの繰返しにより、どんどんとスコアの高い一族が形成されることとなります。
⦅前編終わり⦆






