
株式会社エイゾスのノーコードAIソフト「Multi-Sigma」でできる、AI学習(モデル作成)、要因分析、AI予測、最適化、そして、最新機能のベイズ最適化を実際のデータを使って試してみる記事の後編です。
【ツール】
今回使用するツールは、
・Multi-Sigma:多目的変数に対する最適化を行うことができるノーコード AI解析プラットフォーム
です。
【課題】
最適化の課題と要因分析も含む課題の2つを用意して実行しました。
1.
alvaModelに於けるモデル自動生成ハイパーパラメータの最適化(前編)
2.
The Boston houseに於ける要因分析と最適化(後編)
後編では、課題2について見て行きます。
【課題2. The Boston houseに於ける要因分析と最適化】
(ア) データセット
-
The Boston house-price data
-
統計解析や機械学習でよく使われるボストンの住宅価格データです。1978年に米国国勢調査局の情報を抽出加工して作成・公開されたデータセットで、大気汚染の公害が大きな問題であった米国において、よりクリーンな空気への要求をボストン市街地に於ける住宅データを使って検討する論文に使用されました。
http://lib.stat.cmu.edu/datasets/boston
-
このデータセットは、13の説明変数から1つの目的変数(住宅価格)を推測する回帰分析データとして良く使われてきました。(目的変数をNOX: NOx濃度とする場合もあります。)今回は多目的変数とするため、住宅価格の他に部屋の数を説明変数から目的変数に変え目的変数を2つとしました。住宅価格と部屋数は元データ全体で相関係数0.70の正相関があり、独立変数とは言えませんが、例題ということで設定しました。説明変数は倫理的に不適切なBという変数を除外し、11としました。
- 全部で506レコードあるうち、20%にあたる101レコードを検証用として取り分け、残りの405レコードをAI学習用(トレーニング/テスト)として使用しました。検証用のレコードは、ExcelのRAND関数を使って発生させた乱数をRANK.EQ関数により順位付けし上位101個を選択しました。ExcelのRAND関数はSEED値を指定できず何かの操作を行う度に再計算され値が変わってしまうので、早めに値だけコピーして結果をフィックスした方が良さそうです。
(イ) 課題
-
2つの目的変数(住宅価格と部屋数)に対して11の説明変数がどのように寄与しているかの要因分析。
-
最小の住宅価格で最大の部屋数を得るための最適化。
それでは、Boston houseのデータを使ってMulti-Sigmaを実行させます。
AI学習
プロジェクトの作成からAI学習までは前編と同じ手順で進みます。
今回はデータ前処理をNormalizationにして確定、実行させます。[図26]

その結果、5つのモデルが出来ました。今回のデータではRMSEの値はモデル間で大きな違いはないようです。[図27]

AI予測と検証
それでは、このモデルを使い、入力ファイルに検証用データを指定してAI予測を行ってみます。使用するモデルはRMSEが最小のモデル4とします。[図28]

〔保存〕ボタンを押下すると実行が始まり、PROCESSINGから赤いDONEの表示に変わればAI予測が完了です。[図29][図30]
〔DONE〕をクリックすると予測結果が表示されます。
 [図29]
[図29]  [図30]
[図30]RMとPRICEの目的変数2つをそれぞれ縦軸と横軸に取り、予測結果をグラフ表示させてみます。[図31]

次に、PRICEを縦軸にAGEを横軸に取りグラフ描画させてみると、無相関のような散布図となりました。[図32]

「グラフ」の更に下に、「検証」という項目があります。〔検証する〕ボタンを押下すると、実測値と予測値を比較した検証が行われます。[図33]

検証結果は目的変数毎の誤差として表されます。表示される誤差は、
相対誤差 = |(実測値 – 予測値)/予測値|
で計算された各レコードの誤差の平均(%)となります。[図34]

この検証結果からは、PRICEよりRMに対する予測の精度の方が高いことがわかります。
予測結果は「結果ファイルのダウンロード」のリンクからcsvファイルとしてダウンロードできます。ダウンロードしたファイルをExcelで開き、目的変数RM、PRICEそれぞれの実測値をX軸にとり、残差(実測値-予測値)をY軸にとってグラフ化してみました。[図35][図36]
 [図35]
[図35] [図36]
[図36]RM、PRICE共に、実測値の大きい所で残差が大きくなっていることがわかります。
また、RMをY軸、PRICEをX軸にとった平面上で実測値の分布と予測値の分布を比較してみました。[図37]
 [図37]
[図37]図35、図36で残差が大きかった部分以外では、概ね分布が重なっていることがわかります。
要因分析
次に要因分析を行います。
説明変数の入力値が表示され、その下に「設定」としてモデルが表示されます。モデル4を選択し、〔実行〕ボタンを押下します。[図38]

要因分析はすぐに終わり、目的変数毎の寄与率が表示されます。寄与率は、正の寄与と負の寄与に分けて%表示され、その合計が目的変数の寄与率%となり、目的変数の寄与率を合計すると100%となります。[図39][図40]


要因分析の結果もcsvファイルとしてダウンロードできますので、Excelで開き、グラフにしてみました。2つの目的変数共に、LSTAT(低所得者人口の割合)とDIS(主要施設への距離)の負の寄与が大きいことがわかります。つまり、低所得者人口が低い地区であるほど、主要施設への距離が遠い地区であるほど、部屋数が多く住宅価格が高くなることを示しています。
また、RMにはCRIM(地区別の犯罪率)の正の寄与、PTRATIO(町別の生徒と先生の比率)の負の寄与も比較的大きいことがわかります。PRICEに対しても似たような傾向ですが、RMと比べると寄与はそれほど大きくはないようです。[図41][図42]
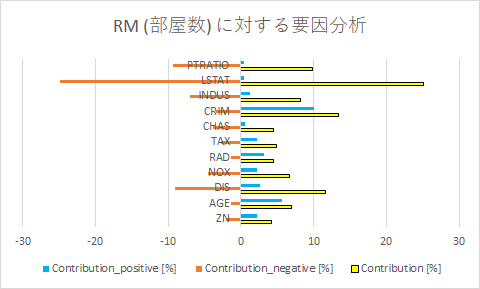 [図41]
[図41] [図42]
[図42]最適化
では、この課題の最後として最適化を実行します。
出力値の設定は、RMを最大化、PRICEを最小化とします。つまり、より部屋数が多い住宅をより安い価格で手に入れるためにはどのような所に住めば良いか、という現実的な問題からの設定となります。[図43]

入力値を確認したら[図44]、

設定でモデル4を選択し、[図45]

遺伝的アルゴリズムのパラメータはデフォルトのままにして〔保存〕ボタンを押下します。[図46]

最適化が終了しましたので、縦軸にRM、横軸にPRICEを指定しグラフ表示させてみます。[図47]

これは、部屋数が多ければ価格は高いという当たり前の結果が出て来たように見えます。
RM(部屋数)とPRICE(住宅価格)は正相関があるので、RMが最大かつPRICEが最小となる点はこの中にはなく、RMを大きくしようとすればPRICEは小さくならないというトレードオフの関係にあります。
そのため、最適化とは言っても1つの最適解が存在するわけではありません。そこで、RMとPRICEの組合せが存在しうる空間の中で最外周部に位置するバランスの異なる複数の解、すなわちパレート解を求めることが重要となります。
そこで、〔結果ファイルのダウンロード〕から最適化結果データをダウンロードし、Excelで加工してみます。結果は、指定した10世代に対し1世代あたり20ずつの最適化結果、計200レコードの重複を含むデータとなります。このデータを用いて図47と同じ散布図を描画し、周辺の点と比較してRMがより大きく、PRICEがより小さい点をパレート解として抽出してみました。[図48]
 [図48]
[図48]このグラフに元データを加え、パレート解を結んだ線をパレートフロントとして書いてみます。[図49]
 [図49]
[図49]元データと比較して見ると、最適化の結果はRMがより大きく、PRICEもより大きい領域に散布していることがわかり、パレートフロントはその限界線となっています。
ここで、このパレート解が説明変数空間でどう位置付けられているかを見るために、要因分析で寄与率が一番大きかった要因LSTATと2番目の要因DISを軸に取り、元データの散布図上にプロットして見ます。[図50]
 [図50]
[図50]最適化のデフォルト設定では、各説明変数の最小値と最大値の間の値を取るようになっていますので、その範囲から出ることはないのですが、この図を見ると、LSTATとDISという2つの説明変数に限って言えば、パレート解となった点がほぼ元データの領域に入っていることがわかりました。
プロファイリング
タスク作成画面(プロジェクトのホーム画面)から、学習データの統計解析であるプロファイリングを作成することができます。[図51]
.png)
〔プロファイリングを作成〕ボタンを押下すると、プロファイリングを作成中の表示に変わります。[図52]
 [図52]
[図52]また、画面上部にページを再読み込みして、作成が完了したかどうか確認してくださいとのメッセージが出ます。[図53]

尚、スタートアップガイドによると、「説明変数の数が多くなると、プロファイリングの作成が終わらない可能性があります」とありますが、2022年10月上旬にツールの簡素化の改修がなされ、以前はプロファイリングが作成できなかったBoston houseのデータが持つ11個の説明変数+2個の目的変数でもプロファイリングが使用できるようになっています。
ページを再読み込みして〔プロファイリングを開く〕の表示になれば、プロファイリングは完了しています。[図54]
 [図54]
[図54]〔プロファイリングを開く〕をクリックするとPandasのレポート画面が新しいタブで表示されます。[図55]
 [図55]
[図55]レポートはOverviewセクションとVariablesセクションに分かれています。[図56、図57、図58]

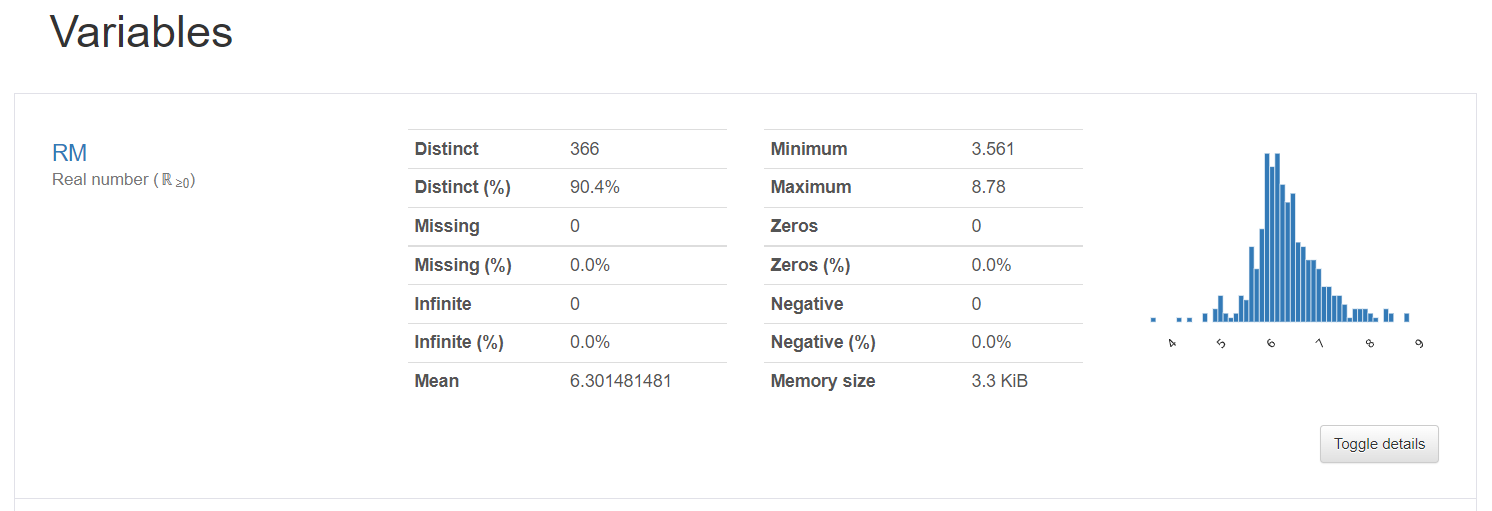

Variablesセクションには、目的変数(output)と説明変数(input)の全てが表示されます。
各変数の右下にある〔Toggle details〕ボタンを押すと、更に詳細な統計情報が表示されます。[図59]

Variablesセクションの最後には、変数間の相関関係を示すチャートが表示されます。[図60]

プロファイリングを使えばAI学習や最適化に使用している変数がどのようなものであるかが一目でわかるようになりますので、分析の全体像をプレゼンする際などにとても役に立つ機能だと思われました。
≪終≫






