
株式会社エイゾスのノーコードAIソフト「Multi-Sigma」でできる、AI学習(モデル作成)、要因分析、AI予測、最適化、そして、最新機能のベイズ最適化を実際のデータを使って試してみました。
【ツール】
今回使用するツールは、
・Multi-Sigma:多目的変数に対する最適化を行うことができるノーコード AI解析プラットフォーム
【課題】
最適化の課題と要因分析も含む課題の2つを用意して実行しました。
1.
alvaModelに於けるモデル自動生成ハイパーパラメータの最適化
2.
The Boston houseに於ける要因分析と最適化
前編では、課題1についてまとめて行きます。
【課題1. alvaModelに於けるモデル自動生成ハイパーパラメータの最適化】
(ア) データセット
-
alvaModel #column optimization
data(自作)
-
Alvascience社のQSAR/QSPRモデル作成ソフトalvaModelで、自動モデル生成を行う際に指定する分子記述子の数(column数)を説明変数とし、できたモデルのスコア(トレーニングとテストのR2とRMSE)を目的変数としたデータセットです。([1説明変数×6水準×8繰返し]×[4目的変数])
-
元データとなるVEGA ToolkitのFate & DistributionセクションのBiodegradability(生分解性)にある、Persistence (water) quantitative modelの回帰モデル用223個のデータセット(178個のトレーニングデータと45個のテストデータ)に対し、予め分子記述子計算ソフトalvaDescで計算し変数削減した460個の記述子データを組み合わせたプロジェクトファイルをalvaModelに投入しました。
-
alvaModelで生成するモデルはPLS(部分的最小二乗回帰)とし、自動生成のパラメータであるcolumn数(説明変数として使う記述子の数)を5~30の間で5刻みに変え、R2を目的スコアとして自動生成を実行しました。各自動生成で生成されたモデルの上位8つを保存し、各モデルのスコア(R2/RMSE×トレーニング/テスト)を記録しデータ化しました。
-
alvaModelの使い方については、弊社ブログ「Alvascience社Software Suite:alvaDesc/alvaModel/alvaRunnerの連携使用」をご覧ください。
https://www.affinity-science.org/2022/06/alvasciencesoftware-suitealvadescalvamo.html
(イ) 課題
-
トレーニングのR2とテストのR2を共に最大化するcolumn数の探索を、AI学習に基づく最適化とベイズ最適化の両方で行う。
※ alvaModelのモデル生成では、説明変数として使われる分子記述子について、どのような記述子を採択するかが重要です。しかし、何個の記述子を指定したらより効率的で良いモデルを得られるのかという実際的な疑問もあり、モデルの種類を固定した時のハイパーパラメータである記述子数の最適化問題として設定しました。
それでは、alvaModel #column optimization dataを使ってMulti-Sigmaを動かして行きます。
プロジェクトの作成
投入するデータセットは全部で48レコードの簡単なものです。[図1]
 [図1]
[図1]この形のままではMulti-Sigmaで使えませんので、説明変数だけのcsvファイル(Input file)と目的変数だけのcsvファイル(Output file)に分けて保存します。
入力ファイルが準備できたらMulti-Sigmaのダッシュボード画面で「プロジェクトを作成」を選択し、プロジェクトの作成を行います。
解析手法はAI解析とベイズ最適化の選択ができますが、ここではまず、ニューラルネットワーク解析と多目的遺伝的アルゴリズムを行うAI解析を選択します。プロジェクト名を付け、先ほど準備したインプットファイルとアウトプットファイルを指定し〔保存〕ボタンを押下すればプロジェクトが作成されます。[図2]
 [図2]
[図2]タスクの作成
ダッシュボード画面で作成されたプロジェクトを開き、「タスクを作成」をクリックし、分析のタスクを設定します。
 [図3]
[図3]作成されたタスクの「データ前処理」〔設定〕ボタンを押下してデータ前処理の設定に移ります。デフォルト設定では全てMax-Minとなっています。これで良ければ〔確定〕ボタンを押下します。[図4]
 [図4]
[図4]尚、データ前処理については、ダッシュボードから開ける「スタートアップガイド」9ページに詳細説明がありますので、参考にして下さい。
AI学習
次に、いよいよAI学習に入ります。AI学習のスタートボタンを押すと、AI設定画面に変わります。[図5]
 [図5]
[図5]AI学習をデフォルト設定のままで実行させる場合は、画面の上の方にある〔自動設定〕ではなく、画面の一番下にある〔保存〕ボタンを押下すると画面左のバーに実行状況が表示されます。[図6]
 [図6]
[図6]処理は数分で終わり、〔DONE〕が表示されます。[図7]
.png) [図7]
[図7]AI学習が終わると、画面の下の方にAIモデルが表示されます。RMSEがモデルを評価するスコアとなりますので、値がより小さいモデルの性能が高いということになります。[図8]
 [図8]
[図8]作成された5つのモデルの平均スコア(RMSE)が0.138と小さい数値になっており、誤差が比較的小さなモデルが生成されたことがわかります。
尚、AI設定画面の上の方にある〔自動設定〕ボタンを押下すると、より精度よくAI学習が実行されます。その場合、AI学習がバッチジョブのような感じとなり終了まで数時間かかってしまいますので、例えば、夕方にジョブを走らせて翌朝に結果を確認するというような使い方がお勧めです。
ちなみに、今回使用しているデータでAI学習を自動設定で行ってみました。生成されたモデルのRMSE平均はデフォルト設定では0.138でしたが、自動設定の場合に10個生成されるモデルの平均は0.127、RMSEが一番小さいモデルはデフォルト設定では0.094でしたが、自動設定では0.067とわずかですが誤差がより小さくなっていました。
また、自動設定で学習させた後に設定パラメータを見ると、デフォルト値とずいぶん違っていることがわかります。[図9]
 [図9]
[図9]特に、隠れ層の数が1から4へ、隠れ層のニューロン数が10から21へと大きくなっていることがわかります。
最適化
モデルが出来たので、最適化を実行します。最適化の〔START〕ボタンを押下すると、最適化設定画面となります。ここで、目的変数として入力した変数(出力値)を最大化するのか、最小化するのかを設定します。「非制御」という選択肢がありますが、これは、その変数を最適化に使用しないという設定になります。「目標値」はテキストフォームに入力した数値に近い解を優先的に探索するという選択肢になります。[図10]
また、その下の「設定」にある「アンサンブルモデル」と表示されている枠の中で、使用するモデルを選択します。複数のモデルを選択するとアンサンブルモデルとして使用されます。
ここでは、まず目的変数をトレーニングのR2の1つとし、スコアが小さかったモデル1と4のアンサンブルモデルを使用して最適化を行ってみることにします。[図11]
画面の更に下に多目的遺伝的アルゴリズムの為のパラメータ設定[図12]がありますが、デフォルトのまま、〔保存〕ボタンを押下し、最適化を実行します。

[図10]

[図11]
 [図12]
[図12]
最適化の実行が終了すると、同じ画面の下の方にグラフを表示できるようになります。ここでは、縦軸に目的変数であるトレーニングのR2を、横軸に説明変数であるcolumn数を指定し描画させました。[図13]
 [図13]
[図13]グラフを見ると、column数16くらいの所に極大値を持ち、全体とするとcolumn数5から30までほぼ単調増加している結果となりました。最大化に対する説明変数columnの値は30ということになります。
次に、4つの目的変数全部を使用し、トレーニングとテストのR2を共に最大化、トレーニングとテストのRMSEを共に最小化とてAI学習を実行します。 [図14]

[図14]
1つの目的変数で最適化した時と同様に、縦軸に目的変数であるトレーニングのR2を、横軸に説明変数であるcolumn数を指定し描画させてみます。[図15]
 [図15]
[図15]目的変数としてR2-Trainingだけを最適化した場合と同じグラフになりました。
次に、縦軸に目的変数であるテストのR2を、横軸に説明変数であるcolumn数を指定し描画させます。[図16]
 [図16]
[図16]トレーニングのR2とは逆のほぼ単調減少のグラフとなりました。 最大化に対する説明変数columnの値は5となりました。
最適化結果は〔結果のダウンロード〕からcsvファイルとしてダウンロードできます。Excelで開いてトレーニングのR2とテストのR2がcolumnに対してどういう関係になっているかを見るためにグラフ化してみました。[図17]
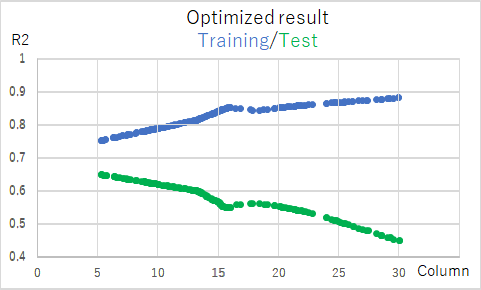 [図17]
[図17]トレーニングのR2(青)とテストのR2(緑)は鏡像のような形をしていますが、トレーニングのR2がcolumn=17あたりから緩やかに上昇しているのに対して、テストのR2の方がより急激に下降していることがわかります。これは、トレーニングのデータを使ってalvaModelがモデル生成する際、説明変数の数を増やしていくと性能は上がりますが、それと同時にトレーニングデータを過学習した結果、テストデータに対しては当てはめが急激に悪くなっていく傾向であることを示唆していると思われます。
また、このグラフからトレーニングのR2最大化とテストのR2最大化は相反する関係であることがわかります。
では、最適化結果としてこれらトレーニングのR2とテストのR2がどのような関係になっているかをMulti-Sigmaでグラフ描画させてみます。[図18]
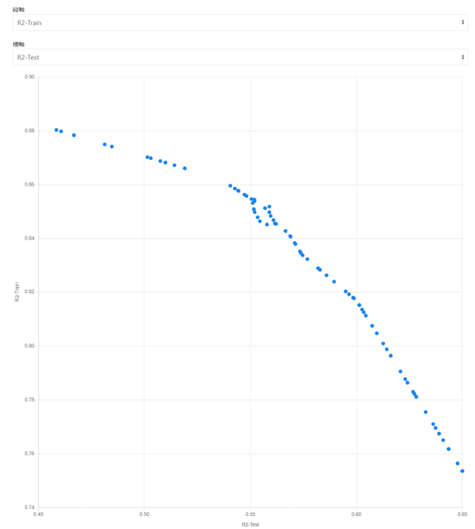 [図18]
[図18]トレーニングのR2とテストのR2の関係は双曲線のように右上に凸な曲線になりました。
このモデルに基づく最適化結果からは、トレーニングとテストのR2を共に最大化することは出来ず、2つの目的変数はトレードオフの関係にあり、お互いにそこそこの所で妥協せざるを得ないことがわかります。また、最適化結果の点は、トレードオフの関係にある2つの目的変数を最適化した組合せであるパレート解、点を結ぶ曲線はパレートフロントであると解釈できます。[図19]
 [図19]
[図19]このパレート解の中で、トレーニングとテストの妥協点を探りたいのですが、トレーニングのR2をより大きくしようとしても、0.82以上にすると該当する解がないことがわかります。[図20]
 [図20]
[図20]そこで、
トレーニングのR2≧0.8 &
テストのR2≧0.6
としてみると15点が領域にはいることがわかります。[図21]
 [図21]
[図21]これら15点を準最適点としてピックアップし、データを見てみると、columnの値は整数にして11~13となっていることがわかります。[図22]
 [図22]
[図22]column数が整数にして12と13の間ではテストのR2があまり変わらないので、トレーニングのR2をより大きくするならばcolumn数は13ということになります。
つまり、トレーニングのR2とテストのR2をバランス良くしたい場合、最適なcolumn数は13ということになりました。
ちなみに、column数を13に設定して実際にalvaModelでモデル自動生成を行った結果、上位3モデルの平均スコアは、トレーニングのR2=0.834、テストのR2=0.646 となりました。
ベイズ最適化
次に、最新機能のベイズ最適化を試してみます。
ベイズ最適化はニューラルネットワークを使ったAI解析とは別のアプリケーションとなり、新たにプロジェクトから作成する必要があります。プロジェクトの作成時に解析手法としてベイズ解析を選択します。[図23]
 [図23]
[図23]また、ベイズ最適化では目的変数は2つまでという制約がありますので、outputファイルを作り直してトレーニングのR2とテストのR2の2変数とします。また、説明変数は10まで、データ数は50まで、データ数+候補数は55までという制約もあります。今回はデータ数が48のため、候補数を7としました。[図24]
 [図24]
[図24]ベイズ解析はAI学習よりも時間がかかる感じですが、それでも12~3分で最適化が終了しました。 [図25]
 [図25]
[図25]候補の数は7に設定したのですが、結果として7つの候補はほぼ同じ値となりました。 [図26]
 [図26]
[図26]グラフ表示させると7点が並びますが、軸のスケールを細かく取っていますので、実質的には1点となります。[図27]
 [図27]
[図27]これから、ベイズ最適化結果は、
-
column=30.0の時に、トレーニングのR2=0.900、テストのR2=0.528
となりました。
alvaModelでのcolumn=30は入力データにありますが、ベストモデルはトレーニングのR2=0.918、テストのR2=0.480でしたので、遠からずの最適化予測結果であったかと思われます。
より少ないデータでのベイズ最適化
ベイズ最適化は少ないデータからでもそれなりの良い解を提供してくれる強力な手法とも言われます。
そこで、今回投入した48個のデータからcolumnの各水準3個だけ、計18個のデータのサブセットをベイズ解析にかけてみました。
その最適化結果は、
-
column=30.0の時に、トレーニングのR2=0.915、テストのR2=0.519
となりました。[図28]
 [図28]
[図28]これは上記48個のデータからの最適化結果
-
column=30.0の時に、トレーニングのR2=0.900、テストのR2=0.528
にかなり近い結果となっており、確かに少ないデータからでも良い解を提供できる強力な手法のようです。
≪後編へ続く≫






