Alvascience社のソフトウェアスイートを使用してQSAR/QSPRに使用する回帰モデルを作成・検証し別のデータセットに適用する手順について、前編では実際のデータを使ってモデルを生成するところまででしたが、後編ではモデルの処理と出来上がったモデルの検証と適用について説明していきます。
【alvaModelによるモデルの処理とエクスポート】
・KNN法で生成されたモデルでのK値最適化
KNNでのモデル生成は近傍の分子数をデフォルトの5で行いましたが、念のため、ベストモデルのKNN 15でK値の最適化を走らせてみます。K値を2から20まで変えてスコアを比較すると、もともとのK=5でR2の値が最大となっているため、K値を変更する必要はないという結果になりました。[図17]
 [図17]
[図17]・コンセンサスモデルの作成
次に、PLSで保存したベストモデルと、KNNで保存したベストモデルを組み合わせたコンセンサスモデルを作ってみます。できたコンセンサスモデルはトレーニングのR2はSVMのベストモデルより低いものの、テストのR2はより高くなっています。[図18]
 [図18]
[図18]・ADの設定
ベースとなるモデルができあがったので、モデルの信頼度を高めるため適用範囲(AD:
Applicability Domain)を設定します。
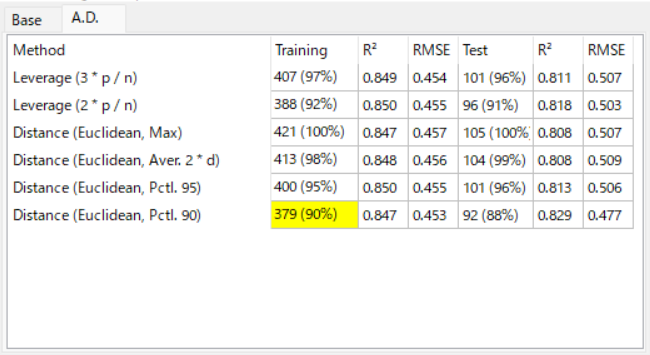
まずモデル4に対してalvaModelで用意されているAD設定手法、てこ比、距離ベース(max、平均、パーセンタイル)の全てを適用してみます。てこ比はファクター3と2、パーセンタイルは95と90としました。その結果を見ると、AD設定前と設定後で、トレーニングセットでのスコアは殆ど変わりませんが、テストセットではスコアが向上していることがわかります。[図19]
ADの表で黄色く表示されているものが現在アクティブになっているADとなります。
 [図19]
[図19]チャート上では、ADから外れた分子がオレンジ色で表示されます。ADに入ったトレーニングは緑、テストは青となります。[図20]
 [図20]
[図20] また、てこ比でのAD設定の様子はウィリアムズプロットで確認できます。[図21]
 [図21]
[図21]ここで設定したADの中では、90パーセンタイルでのADでテストセットでのR2とRMSEが最良になっているため、ADとして90パーセンタイルを採用することとします。
・コンセンサスモデルのAD設定
先ほど作成したPLS12とKNN15のコンセンサスモデル18にもADを設定したいのですが、元となるモデルの全てにADが設定されていないとコンセンサスモデルのADは設定できません。そこで、まず元のモデル12と15にもADを設定します。今回はモデル12と15に、それぞれ閾値3のてこ比でADを設定しました。その上で、ADが設定されたモデル12と15を使用して、再度コンセンサスモデルを作ります。これで、ADが設定されたコンセンサスモデル19ができました。
元となるモデルが複数のADを持つ場合、それぞれのモデルでアクティブになっている(黄色く表示されている)ADに基づいてコンセンサスモデルのADがブーリアンのANDで設定されます。(分子Aがモデル1のAD内にあり、かつモデル2のAD内にある時、モデル1+2のコンセンサスモデルのAD内にある。)それぞれのモデルのADタイプが違っていてもかまいません。 [図22]
 [図22]
[図22]・モデルのエクスポート
alvaModelでのモデル作成の最後として、モデルをエクスポートします。ここでは、SVM4(AD付き)のモデルと、PLS12とKNN15で作ったコンセンサス19(AD付き)のモデルの2つをalvaRunnerプロジェクトファイルとしてエクスポートします。[図23]
 [図23]
[図23]これでalvaModelのお仕事は終了です。
【alvaRunnerによるモデル適用】
alvaModelで作成したモデルを、alvaRunnerを使用して他の分子セットに適用して予測を行います。
・モデルの検証
まず、alvaRunnerのOpen
projectから先ほどalvaModelからエクスポートしたモデルを導入します。[図24]
 [図24]
[図24]ここにOpen moleculesメニューから対象化合物を導入します。はじめに、元々のデータセットから分けておいた検証用の105個のデータを入力してみます。計算は一瞬で終わりました。[図25]
 [図25]
[図25]橙色で表示されている分子はそのモデルのAD外であることを意味しています。
この結果をExport resultsからタブ区切りテキストファイルとして出力します。Excelから開くとこのようになります。[図26]
 [図26]
[図26]この結果に、それぞれの分子に対する実験値をマージしてベリファイ(検証用)データでのR2を計算してみました。トレーニングでのスコアに比べてみると、ベリファイでは低くなっていますが、モデルCons19でADを適用した時にはトレーニングより良い値となっています。[図27]
 [図27]
[図27]RMSEを見てみると全データではベリファイが大きくなっていますが、R2と同様に、モデルCons19でADを適用した時にはトレーニングより良い値となっています。[図28]
 [図28]
[図28]・モデルの適用
最後に、このモデルを米国の連邦水質汚染防止法に関連する有害物質“40 CFR 116.4 Designation of Hazardous Substances” 333化合物の内、SMILESレコードがある290化合物に適用してみます。[図29]
 [図29]
[図29]予測結果をエクスポートしてExcelで開き確認してみます。予測結果にSVM4とCons19の二つのモデル共にnaとなっているものが多いことに気が付きます。入力した290化合物のうち、159個がnaでした。
[図30]
また、予測値が計算された131個の中で、ADに入っているものはSVM4で94個、Cons19で101個という結果となりました。
 [図30]
[図30]一度、alvaModelのプロジェクトに戻り、それぞれのモデルで使われている記述子を確認したところ、4つの記述子が2つのモデルに共通して使われていました。alvaDescに40 CFR 116.4 Designation of
Hazardous Substancesのデータを入力し記述子を計算させ、これら4つの記述子を出力させたところBLTA96でnaが多く出ていました。投入したSMILESを確認してみると、”.”が入った非完全結合型の分子ということがわかりました。[図31]
 [図31]
[図31]alvaDescのユーザーマニュアルによるとBLTA96は非完全結合型の構造では計算できません。非完全結合型の分子を含んでいないKM_ARNOTデータセットに基づいて生成されたモデルの中に、非完全結合型分子に対応できない記述子が採用され、そのモデルを非完全結合型の分子を多数含むEPAの40CFRデータセットに適用したため、そのような結果となったようです。
また、モデルに使用されている記述子の中で、これら共通する4つの記述子以外にも投入した40 CFRの分子に対してnaとなる記述子がいくつかありました。
予めわかっていれば、alvaModelでのモデル自動生成の際に選択対象とする記述子から望ましくない記述子を外しておくことで、より幅広い化合物に対応できるモデルの生成ができるようになると思われます。
では次に、Cons19のモデルでの予測の妥当性を確認してみることにします。まず、予測値をヒストグラムにしてみると結果が広い範囲にばらついていることがわかります。[図32]
 [図32]
[図32]今回予測した値は、化学物質の魚類に於ける生体内変換率を、取り込んだ物質の半減期の常用対数とした速度定数kMであり、その値が高くなれば生物濃縮により生体毒性が高まると考えられます。
一方、適用したEPAのデータは水質汚染に於ける有害物質のリストであり、それぞれの物質についての生物活性や生物濃縮を評価しています。
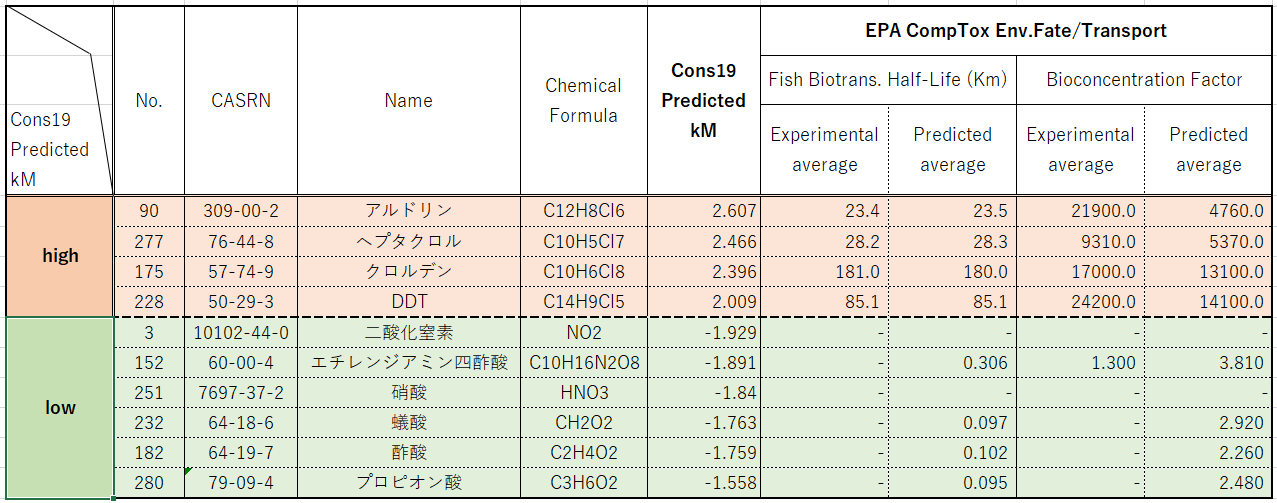
そこで、kM予測値の上位と下位の4化合物ずつについて、それぞれデータの出所であるEPAのサイトに掲載されている生物濃縮の情報と突き合わせてみました。生物濃縮の情報としては、各化合物の” Env. Fate/Transport”カテゴリー内に表示されている” Fish
biotransformation half-life (Km)” と” Bioaccumulation
factor (BCF)” の実験値平均と予測値平均を用います。尚、kM予測値の下位4化合物については、そのうち2つにEnv.Fate/Transportカテゴリーに記載がありませんでしたので、更に広げて下位6化合物を見てみました。
kM予測値上位の4化合物についてはEPAによる生物濃縮データに於いてもFish Biotransformation、BCFに於いても共に高い値となっています。
kM予測値の下位6化合物のうちデータのある4化合物については、” Fish biotransformation half-life (Km)” と”
Bioaccumulation factor (BCF)” の実験値は殆ど掲載されていなかったものの、予測値は極めて低い値を示していることがわかります。
[図33]
 [図33]
[図33]これらからkM予測値はEPA ConpTox
Env.Fate/Transportによる生物濃縮と同じ傾向を示しており、生成したモデルをEPAの化合物に適用した結果は妥当なものであると考えられました。
End






