2021年12月から販売開始したVEGA Toolkitの基となっているQSARモデルVEGAについて、その使い方をまとめてみました。
まず、VEGAとは?から説明します。
VEGAとは
VEGAは、化学物質の有毒性、生物濃縮性、環境特性、物理化学特性など、多様なエンドポイントを予測するQSARモデルが多数搭載されているオープンソースのアプリケーションです。提供されているモデルは、異なるアプローチとトレーニングデータセットにより構築されたもので、トレーニングデータセットを含むモデル情報も同時に提供されています。
また、VEGAはいくつかの汎欧州プロジェクトの枠組みの中で資金提供を受け開発されており、化学物質・化粧品・食品添加物の評価に関わるREACH規制*1ガイドラインの中で、in-vivo試験を避けるために使われるin-silicoツールの1つとして紹介されています。出力されるレポートもガイドラインに従っています。
95個のモデルが含まれる最新版VEGA-GUI-1.2.0はベータ版が公開されており、JAVAをサポートする全てのプラットフォーム上で動作させることができます。
このVEGAをワークフローに組込んで使用できるようにしたものがVEGA Toolkitということになります。
準備
次に、VEGAを使うための準備について、Windowsを例にとって説明します。
1. JAVAの確認
(ア) VEGAを使用されるPCにJAVAがインストールされている必要があります。JAVA 11以上、または、JAVA Runtime Environment (JRE) バージョン 7以上がインストールされているかどうか確認してください。既にインストールされていない場合、新たにインストールする必要があります。
(イ) OpenJDKインストーラを使用してJAVA 11以上をインストールして下さい。最新版のOpenJDKは、https://jdk.java.net/ または https://openjdk.java.net/ より入手できます。若しくは、最新のJREをインストールしてください。最新のJREはwww.java.com から無料でダウンロードできます。
2. アプリケーションのダウンロード
VEGAHUBサイトの"Download
VEGA QSAR Applications"ページにあるダウンロードボタンを使ってアプリケーションをダウンロードします。
現在は、最新版VEGA ver. 1.2.0 ベータ版と安定版ver. 1.1.5 48のダウンロードボタンがあります。ここでは、最新版ver. 1.2.0ダウンロードボタンからvega-GUI-1.2.0.zipをダウンロードします。
https://www.vegahub.eu/download/vega-qsar-download/
3. zipフォルダの展開
ダウンロードしたzipフォルダを全て展開します。アプリケーションのインストール等は必要ありません。
4. VEGAの起動
VEGA-GUI-1.2.0を起動するには、展開したフォルダにある Vega-launcher-WIN.bat
をコマンドプロンプトから走らせるか、または、フォルダの中にある Vega-GUI-1.2.0.jar をダブルクリックします。

使い方
アプリケーションが起動しましたので、VEGA-GUI-1.2.0の使い方について説明していきます。
1. 対象化学物質の入力(INSERT)
(ア) “Insert SMILES:”の下にある入力ボックスに対象化学物質をSMILESフォーマットで入力し、右にあるÌボタンを押下します。その後、別のSMILESを入力しÌボタンを押下していくことで複数の化合物を入力できます。Óボタンにより入力したものを削除することもできます。
(イ) “Import File”ボタンを押下することによりファイルから複数のSMILES列を入力することもできます。使用できるSMILESファイルは、.smi 若しくは .txt です。
(ウ) 入力した化合物を選択(クリック)することで、右側の枠に化合物の2次元画像を表示させることができます。

2. 使用するモデルの選択(SELECT)
(ア) 左側にあるSELECTボタンを押下してモデル選択画面に遷移します。
(イ) 全部で95個あるモデルはエンドポイント毎にまとめられています。”Filter models:” “All available endpoints” が表示されているプルダウンメニューを開くことにより、6つに分けられたエンドポイント分類の中から必要な項目のみを表示させることもできます。
利用可能なQSARモデルについては、こちらをご参照ください。
https://www.affinity-science.com/vega-toolkit/#VEGAQSAR
(ウ) モデルの選択は、モデル名の左にあるチェックボックスをクリックすることで行います。”Select all models” のチェックボックスをクリックすると、そのブロックにある全てのモデルを選択することができます。

(エ) 各モデルの左にある”?”をクリックすることで、ダウンロード可能な情報が表示されます。”Training set” の場合、ダウンロードボタンを押下することにより、CAS
No.、SMILES、Training/Test区分、実験値、予測値が含まれるテキストファイルを入手することができます。尚、コンセンサスモデルはそのブロックにあるモデル全てを用いているということで”?”はありません。

3. レポート形式の選択(EXPORT)
(ア) 左側にあるEXPORTボタンを押下してレポート形式選択画面に遷移します。
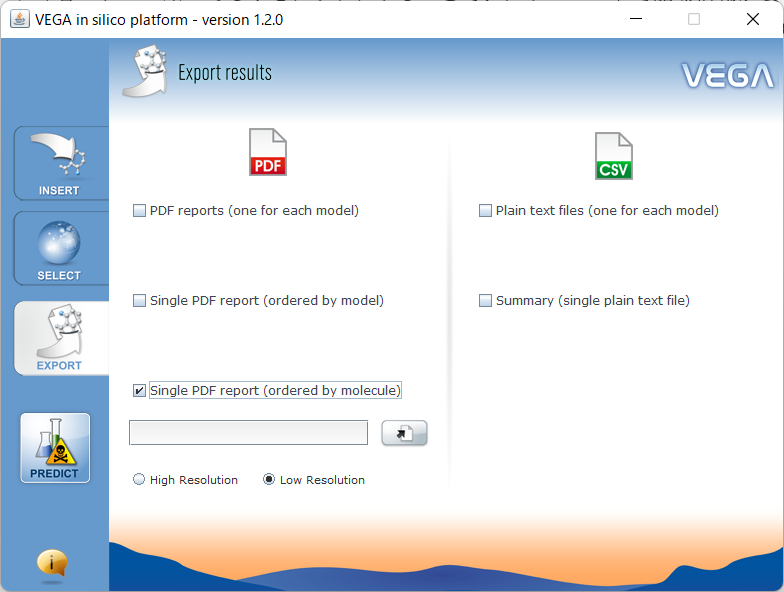
(イ) レポート形式はPDFとCSV(プレーンテキスト)が選択できます。
(ウ) PDFファイルでは、結果の詳細をモデル毎に1つずのファイルとして出力するか、結果全体を1つのファイルに出力するか選択できます。結果全体を単一ファイルに出力する場合、更に、モデル>分子の順に並べる(ordered by model)か、分子>モデルの順に並べる(ordered by
molecule)かを選択できます。後者の分子>モデルの順に並べる単一PDFレポートを選択した場合には、サマリーのテキストファイルも同時に出力されます。
PDFのレポートは、様々な評価結果が表示アイコン、数値、説明文で構成されます。
尚、PDFに入る画像の解像度をHigh ResolutionとLow Resolutionから選べますが、ハイレゾの方が解像度は多少高いもののファイルの大きさは殆ど変わらないので、どちらを選んでも大差はありません。
(エ) CSVファイルでは、結果の詳細をモデル毎のファイルとして出力するか(Plain text
files)か、結果のサマリーのみを1つのファイルとして出力するか(Summary)が選べます。CSVファイルは数値と簡単なテキストメッセージだけで構成されます。
(オ) レポート形式を選択するとフォルダ指定のダイアログが出てきますので、格納するフォルダ(ディレクトリ)を指定します。ファイル名はアプリケーションが自動的につけますので、指定することはできません。
4. アセスメントの実行(PREDICT)
(ア) 左側にあるPREDICTボタンを押下すると計算とレポート作成が開始され、Progress画面に変わります。
(イ) 計算・出力が終了するとかかった時間とともに終了したことが知らされます。

(ウ) 別のレポートを出力させたい場合には、INSERT/SELECT/EXPORT画面に戻り選択してからPREDICTを行います。同じ化合物・モデルに対して複数のレポート形式を指定し、同時に出力させることも可能です。
5. 関連情報の取得(i)
(ア) 左下のiボタンを押下すると、VEGAについての画面が出てきます。

(イ) バージョン情報などが表示されます。”The user’s guide is available (PDF document) 横のダウンロードボタンを押下するとユーザーマニュアルがダウンロードできるようになっていますが、1.2.0 ベータ版ではまだ実装されていません。
レポート
それでは、最後に、出力されるレポートの内容について簡単にまとめます。
使用するモデルにより詳細の内容は違ってきますが、共通する内容としてそのモデルによる予測結果と結果のアセスメントが含まれます。(特性の有無、信頼度、AD(Applicability Domain)に入っているか、トレーニングセットに含まれ実験値が既知の化合物との類似性/結果の一致度など)


CSVのモデル毎ファイルは、PDFレポートにある各項目を数値だけで表示するような形になっています。CSVのサマリーはモデル毎の予測結果と評価が簡単に記された一覧表のような形式です。






